プログラミングでボカロ曲の歌詞を解析して遊んでみた
この記事は、東大ぱてゼミAdvent Calendar 2020 の12月02日公開の記事です。
皆さんこんにちは。はじめまして、れたすです。Twitter は @fairy_lettuce です。
自己紹介
ぱてゼミは 8 期で完走しました。東京大学に理科一類で入学。所属サークルは GUT (東大幻想郷、東方Project好きの集まるサークル) および B4UT (音ゲーサークル) です。
最近は競技プログラミングに熱中しています。競技プログラミングに限りませんが様々な技術について学んでみたいと思っています。
ボーカロイドの話なので軽く音楽的な趣味に触れておきます。好きなボカロPは sasakure.UK さん。好きな曲は『*ハロー、プラネット。』『ワンダーラスト』。ボカロは中高生の頃から知っていましたが、音ゲーに入っている曲を聴いていたらボカロもいつの間にか聴くようになっていました1。
ボカロ以外だと東方Projectが好きです。最近は ALI PROJECT もハマっていてよく聴いています。
序文
昨日 12/01 のラワイルさんの記事『#東大ぱてゼミ とは(ボーカロイド音楽論)』でも紹介されていますが、ボーカロイド音楽論、通称 #東大ぱてゼミ は端的にいうと「人文科学の手法を主に用いてボーカロイド音楽を分析する」という講義です。
ぱてゼミにおいて多様性(ダイバーシティ)は非常に大切にされています。東京大学には文科・理科の区別がありますが、文理の多様性も例外ではありません。ぱてゼミを受講した生徒には文科一類から理科三類までが満遍なく存在しています。
今回は理科一類入学でプログラミングに興味のある者として、ぱてゼミ本講とは違い、コンピュータサイエンスの手法を用いたボーカロイド音楽の分析の可能性を模索します。
それでは始まります。記事の全体は長くなってしまいましたが、専門用語をなるべく省き平易な解説を心がけましたので、お付き合いいただければ幸いです。
やったこと
今回の記事ですが、具体的にしたことを紹介します。
- 歌詞サイトから歌詞を取得する。
- 歌詞を分かち書き(単語で区切る作業)する。
- 分かち書きした歌詞を作曲者ごとに分類し、歌詞に登場する言葉の重要度を計算する。
- 歌詞に登場する言葉から、作曲者どうしの類似度や似た作曲者の分類などを計算する。
以上の全てのプログラミングには C# 言語を使用しています。私は競技プログラミングをしているのですが、それで使っているメインの言語なので書き慣れているからです2。
実際に歌詞を解析してみた
歌詞サイトから歌詞を取得する
まず最初に、歌詞サイトから歌詞をスクレイピング(Web サイトの内容をプログラムで読み込んで解析)します。今回は うたてん というサイトから歌詞を取得しました。
なお、今回は個人の解析目的で使用しています。歌詞には著作権法で保護された著作権が適用されるので、個人利用を越えた範囲での使用はしないようお願いいたします。
スクレイピングには C# で使えるライブラリ(色んな機能をまとめたパッケージみたいなもの)である AngleSharp を用いました。サイトのどこに歌詞データが存在するかを確認しながら、歌詞に相当するデータだけを抜き出すということをここではしています。
実際にどうなるかを以下は童謡の『Believe』で例示します。このリンクから得られる歌詞は実際のテキストではこのようになります。

すごいですね。自分の書いたコードが動くというのはいつでも感動ものです。
分かち書き
次に、得られた歌詞を分析するのに必要な前準備である「分かち書き」をしていきます。これは、日本語の文章を言葉の区切り(形態素)ごとに分けていく作業です。形態素解析とも呼ばれます。
英語では、例えば I have a pen. というように単語ごとが分かれていますが、日本語では分かれていません。「私はペンを持っています。」という文章を解析するためには、「私/は/ペン/を/持っ/て/い/ます/。」というように分ける必要があるのです。これをするのが分かち書きです。
分かち書きには、NMeCab3というライブラリを使用しました。
『Believe』の歌詞を分かち書きして、歌詞の分析に必要無いことば(具体的には名詞・動詞・形容詞・形容動詞以外)を取り除いた結果がこちらです。

とてもすっきりしましたね。これだけではただの単語の羅列ですが、『Believe』の歌詞で特徴的なことばばかりが並んでいるのが分かります。
それでは、この歌詞データを使って実際に解析するパートに入りましょう。面白くなってきます。
言葉の重要度を判定
歌詞データの解析にあたって、言葉ごとの重要度というものを定義します。
ところで、その歌詞やアーティストにとって特徴的な言葉といえば、どのような言葉でしょうか。『Believe』で考えてみましょう。
例えば、「なる」「いる」「時」みたいなあいまいでどんな場所でも使われていそうな言葉はあまり重要で無いですよね。逆に、「希望」「地球」「未来」のような、具体的で他の歌詞にはあまり現れなさそうな言葉は重要そうです。
更に、たくさん現れた言葉も重要そうと考えられます。『Believe』の歌詞ひとつだけではあまり分かりませんが(強いて言えば「未来」「地球」「世界中」などは 2 回出てきていますね)、同じアーティストの歌詞をたくさん集めれば特徴的なワーディングセンスが分かるかもしれません。
このふたつ、「他のアーティストではあまり使われていない言葉である」「その言葉を何回も使っている」という尺度から測った言葉の重要さの指標を TF-IDF と呼びます。Term Frequency (単語の出現頻度) と Inverse Decument Frequency (文章出現頻度の逆4) を合わせた略語です。
なお、具体的な計算式は省略します(こちらをご覧下さい)。難しい式ではないですし、これは既存のライブラリを使用せず自分で実装しました。
これをそれぞれのアーティストごとに単語を集約してまとめ、単語の重要度をそれぞれ計算していきます。
ちなみに、今回調べたアーティストの歌詞に登場する単語で、重要度の上位 10 個を並べてみました(たくさんあるので一部のみです)。

なるほど、確かに各ボカロPの世界観に沿った言葉が多く並んでいるのが分かります。samfree さんは文字通り『ルカルカ★ナイトフィーバー』ですし、うたたPさんの「義務」は『こちら、幸福安心委員会です。』の歌詞に何度も登場しますね。ほかふたりも代表的な曲や特徴的な単語が並んでいるのが分かります。
歌詞の類似度などを判定
単語ごとの重要度が分かりました。今度は各アーティスト毎に出現する単語をもとに、アーティストごとの類似度を求めたりアーティストを分類したりしてみましょう。
アーティストとアーティストの類似度
アーティストの類似度はコサイン類似度で求めます。登場する言葉が重なっていて、その重なった言葉の重要度がどちらも高いと類似度は高くなります。高校数学を知っている人なら、単語の重要度が各次元となっているベクトルどうしの成す角度と言えば分かると思います。
このコサイン類似度で、アーティストどうしの歌詞がどれほど類似しているかを見てみましょう。
下に各アーティストごとの類似度を表にまとめました。類似度が高いほど赤く表示しています。選んだアーティストは独断と偏見です(ゆるして)。なお画像が小さくて申し訳ありませんが、PC ならクリックすると拡大表示されます。
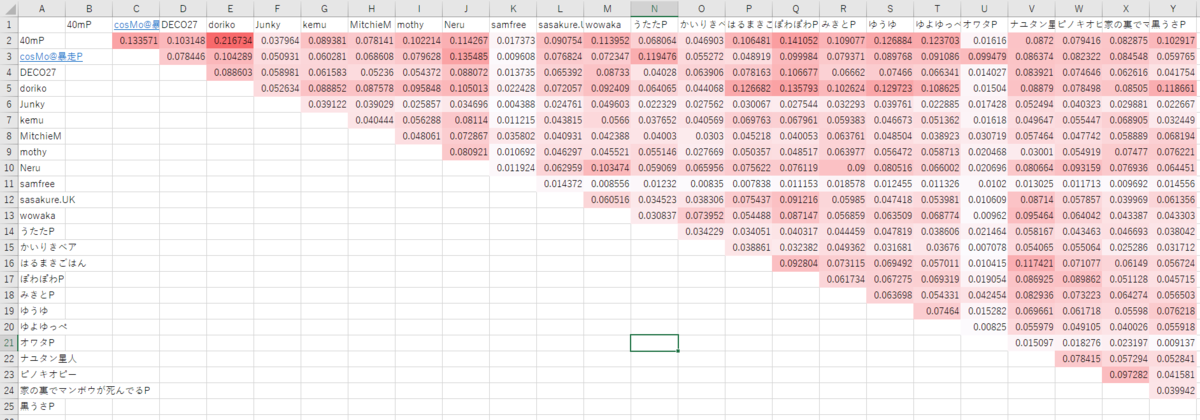 これを見ると、samfree さんやオワタPさん、Junky さんの曲が他のどのアーティストとも類似性があまりないことや、doriko さんと 40mP さんの歌詞が突き抜けて似ていることが分かります。まあ分かる気はします(けど三者の歌詞がどのアーティストとも類似性がない、というのはちょっと謎です、特徴的な歌詞が多いとは思いますが……)。
これを見ると、samfree さんやオワタPさん、Junky さんの曲が他のどのアーティストとも類似性があまりないことや、doriko さんと 40mP さんの歌詞が突き抜けて似ていることが分かります。まあ分かる気はします(けど三者の歌詞がどのアーティストとも類似性がない、というのはちょっと謎です、特徴的な歌詞が多いとは思いますが……)。
他にはぽわぽわPさんと 40mP さん・doriko さん、40mP さんと cosMo@暴走P さんの相関が目立ちます。また名前順なのに上の方に類似度が強いものが固まっている気がします。あまりよくわからない結果ですが、もう少し普遍的に現れる一般的単語を除くようにして、歌詞のデータ数を増やせばより良い結果が得られるかもしれません。
アーティストを分類する
一般的に分類することをコンピュータサイエンスではクラスタリングと呼びます。クラスタリングの解を求めるのはデータの数が大きくなるにつれて計算する時間が爆発的に増えていきますが、今回は近似的な解を速く求められるアルゴリズムである k-平均法5というものを使ってアーティストを分類してみます。
近似的な解なので最初にランダムに解を選んでそこから解をよりよくしていく、というアルゴリズムですが……今回は上手く行きませんでした。今回は先程扱ったアーティストたちを 4 つに分類しようと試みたのですが、このようにほとんどが同じ分類になって、残りの分類は属するアーティストが 1 人のみ、という感じになっています。何度やってもだいたい似たような結果でした。

これはちゃんとした原因がはっきり分かっていて、「次元の呪い」と言われているものです。
ざっくり説明すると、今回は言葉のひとつひとつを次元とするベクトルとして分類しようとしたため、言葉が例えば 500 個存在する歌詞群の中でアーティストを分類するとなると 500 次元ベクトルの距離で分類することになります。一般的に 2 次元や 3 次元のような、低次元のデータほど距離はバラけますが、500 を越える次元では距離はだいたい似たような値に近づいてしまいます。そのため、分類しても意味のない結果ばかりが得られてしまいます。
きちんと近いものを近い、遠いものを遠いと判定するためには、データをなるべく保ったまま次元を落とす作業(「主成分分析」)が必要です。Python などの有名なライブラリではこれをきちんとしているため有用な結果が得られますが、今回は C# でのライブラリを見つけられなかったので断念しました。今後の学習課題としましょう。Python をきちんと学びたいです。
おわりに
今回はボーカロイド楽曲の歌詞をプログラミングで分析してみました。
なお、私は趣味として普段している競技プログラミングはデータ分析と違い、様々な数理的問題を効率的に解くアルゴリズムを「素早く正確に」書く分野です。6
データ分析はあまり詳しくない分野ですが、競技プログラミングではあまり使われない様々なアルゴリズムや知識を得られて非常に楽しかったです。
この記事を読んで、もしデータ分析などに興味を持った方がいらっしゃれば、Kaggle というサイトについて調べてみてはいかがでしょうか。機械学習やデータサイエンスの学習ができ、またコンペティションとして他人と競い合うこともできるサイトです。もちろんこの記事で取り上げた内容よりもたくさんのことを学べます。
(ちなみに、私も Kaggle はやってみたいのですが、競技プログラミングが最近とても楽しく他のことに手を付けられない状態でなかなか手を出せていません。ですが今回のアドベントカレンダー記事の執筆で「意外とできるし楽しい!」ということが分かったので、いずれ挑戦してみようと思います。)
それでは、長くなってしまいましたが、今日の記事はお楽しみいただけたでしょうか。ボーカロイド音楽の分析といっても、分野にとらわれない様々な分析の仕方があります。自分の趣味・興味のある切り口でボーカロイド音楽を研究してみてはいかがでしょうか、というお誘いと体験談でした。
明日 12/03 は、はちじさんの『東方のボカロアレンジを聴いてみた感想』を公開予定です。お楽しみに!